
آنچه در این نوشته میخوانید (فعلاً):
زبان به عنوان زنجیرهای از کلمات
مدلسازی زبان به عنوان زنجیرهای از کلمات چه کاربردهایی دارد؟
- پیشبینی کلمات بعدی هنگام تایپ
- حدس زدن پرسشهای کاربران بر اساس نخستین کلماتشان
- افزایش دقت OCR
- کمک به نرمافزارهای تبدیل صدا به متن
دو رویکرد متفاوت به مدلسازی زبان
یک مثال از شبکه های عصبی (بسیار سادهشده)
پیشنوشت یک: مدت زیادی است که به علل مختلف، از نوشتن دربارهٔ حوزهٔ تکنولوژی فاصله گرفتهام. یکی از علتها این است که معمولاً رویکرد من به تکنولوژی، انتقادی است یا لااقل به جریان اصلی نزدیک نیست. انتقادی نه به این معنا که مخالف تکنولوژی هستم که اتفاقاً عاشق تکنولوژیام. بلکه از آن رو که فکر میکنم نگاه انتقادی میتواند به ما کمک کند تا از ظرفیتهای تکنولوژی، با پرداخت کمترین هزینه (پیدا و پنهان) بیشترین بهتر را بهره ببریم.
اصرار بر نگاه انتقادی به تکنولوژی در ایران امروز ما، میتواند مخرب باشد. چون اظهارنظر در خلاء انجام نمیشود و باید بستر و زمینه را هم دید. وقتی زیرساختهای اصلی ارتباط با جهان به درستی در اختیار ما نیست، فرض کنید کسی بیاید از اثرات منفی شبکههای اجتماعی بگوید. این شکل از حرف زدن، بیشتر از آنکه به کار مردم بیاید، خوراک کسانی میشود که معتقدند حق اتصال به دنیای آزاد را فقط باید با سیمکارتهای ویژه به «خارجیها» داد.
در چنین شرایطی، این که کارشناسی چشم خود را ببندد و بگوید «من فقط میخواهم تحلیلهای علمی و کارشناسیام را بگویم» نه مصداق حماقت، که از جنس خیانت است (و متأسفانه در این مدت هر چند روز یک بار مجبور بودهام این نکتهٔ واضح را به برخی دوستان و عزیزان یادآوری کنم). امروز باید از مزایای اینترنت و دسترسی آزاد به اطلاعات گفت و روزی که این امکانات برای مردم فراهم شد، آن روز دربارهٔ دردسرها و سختیهایش گفتگو کنیم و بکوشیم اثرات منفی استفاده از آنها را مدیریت کنیم.
پینوشت دو: به همین علت هم در این چند سال، به رغم میل درونی دربارهٔ رمزارزها هم چیزی ننوشتم. در حالی که میتوانید تصور کنید برای کسی که مردم جهان را نه بر پایهٔ کفر و ایمان که بر پایهٔ نگاه توزیعشده و نگاه متمرکز در شکلگیری پدیدههای عالم در یک طیف میگنجاند، چقدر سخت است که دربارهٔ یکی از بزرگترین دستاوردهای نگاه توزیعشده به پول چیزی ننویسد و حرف نزند. نمیگویم حرف کارشناسی عجیبوغریبی داشتهام. اما حرفم این است که چه دانشی در دنیا بهتر از سیستمهای پیچیده برای بررسی و تحلیل و ارزیابی نقاط قوت و ضعف و ظرفیتها و خطرات رمزارزها وجود دارد؟ و وقتی افراد بسیاری به اشتباه، اقتصاد کلان را بهترین بستر تحلیل این محصول جدید میبینند، مقاومت در برابر وسوسهٔ نوشتن سخت بوده است. اما میدانستهام که در این مواقع، از ده جمله حرف، نه جمله رها میشود و آن تکجملههایی که از رگولاتوری و تمرکز میگویند، پررنگ میشود و شلاق تنظیمگران غیرمتخصص بر پیکر این صنعت تازه نواخته خواهد شد. باز هم منظورم این نیست که کسی حرف امثال من را جدی میگیرد یا اساساً کسی مثل من حرف خاصی برای گفتن دارد، اما ماهیت این کار – توجیه ساختن برای کسانی که تشنهٔ توجیه رفتارهای توجیهناپذیر خود هستند – چیزی نیست که با روحیات من جور درآید.
پیشنوشت سه – یک : با وجود توضیحاتی که گفتم، تصمیم دارم اندکی دربارهٔ چت جی پی تی بنویسم. علت نخست این است که چند بار در گفتگوهای دوستانه در این باره حرف شده و حس کردم شاید به جای تکرار یک مجموعه حرف ثابت در چند مکالمهٔ مختلف، اگر آنها را کمی بهتر و هدفمندتر در یک ساختار منظمتر بگنجانم، چیز بهتری از آب در میآید.
پیشنوشت سه – دو: علت دوم این که پردازش زبان طبیعی برای من همیشه موضوعی جذاب بوده و از سالها پیش، گاهوبیگاه برایش وقت میگذاشتهام (البته بیشتر کارهایی از جنس رویکرد DCG یا Definite Clause Grammar؛ شبیه چیزی که در واتسون آیبیام توسعه پیدا کرد و با مدلهای زبانی به معنای رایج در یادگیری ماشینی فرق دارند). طبیعتاً به خاطر این علاقهٔ شخصی نگاهی هم به پژوهشهای این حوزه و رویکردهای دیگر – که سهم انسانی در آنها کمتر و سهم Computational بیشتر بوده – میانداختهام. البته حاصل این گشتوگذارها، من را چندان از سطح مخاطب عام این ابزارها فراتر نبرده و حرفها و نظراتم، کارشناسی محسوب نمیشوند.
پیشنوشت سه – سه: بعضی اظهارنظرهایی که در این مدت دربارهٔ Chat GPT شد، آنقدر عجیب بود که نتوانستم در مقابل نوشتن مقاومت کنم. به سه موردشان اشاره میکنم.
یکی آن آقایی که در حضور آقای رئیسی گفت که «با چت جی پی تی مکاتبه کرده» و دربارهٔ شب قدر پرسیده و گفته «بالاخره شب قدر چیز خوبیه یا نه؟ باور داشته باشیم یا نه؟» و البته چت جی پی تی هم – به روایت ایشان – پاسخ داده که «یه اعتقاد شخصیه و …» (+). یادم هست در دوران مدرسهٔ راهنمایی که هنوز کامپیوترها به شکل عمومی برای کاربردهای روزمره رایج نبودند و ما با غرور از این که کمودور ۶۴ حدوداً ۶۴۰۰۰ «تا» حافظه دارد حرف میزدیم، یکی از بستگان – که آدم معتقدی بود و همهچیز را بر آن معیار میسنجید – پرسید: از خدا در موردش پرسیدهای؟ چه میگوید؟ (جهان به پیش میرود. اما عدهای مدام خود را تکرار میکنند).
دوم این که دیدم یک استاد ارتباطات دانشگاه لابهلای صحبتهایش دربارهٔ تهدید شغل خبرنگاری توسط این نوع سرویسها گفته که (+) «آنچه هم که شما در هوش مصنوعی میبینید در زبان انگلیسی است و به زبان فارسی هم به زودی اتفاق نخواهد افتاد. اتفاق عجیبی هم نیست و دیتا خاصی در آن پیدا نمیشود.» البته ایشان به نکات دیگری هم اشاره کردند که بعضاً درست هستند. اما به گمانم در بررسی فرصت و تهدید یک تکنولوژی جدید، این شکل از اطمینان دادن که بالاخره زبان ما آنقدرها هم در جهان زنده نیست و مطالب کمی در آن هست و چون زبانمان در دنیا رواج ندارد، هنوز تهدید جدی برای ما نشده، روش چندان مناسبی نیست. در ارزیابیها باید ظرفیتها را سنجید و نه این که از ضعفهایمان به عنوان نقاط امیدبخش نام ببریم.
سومین مورد هم استوری یکی از دوستان خوبم بود که اتفاقاً در حوزهٔ آیتی هم فعالند دربارهٔ Chat GPT چیزی با این مضمون (دقیق در ذهنم نیست) گفته بودند که بالاخره از چیزی که همزمان آشپزی را به اندازهٔ آشپز میداند و فلسفه را به اندازهٔ فیلسوف و تاریخ را به اندازهٔ مورخ و پزشکی را به اندازهٔ پزشک و … باید ترسید (به معنای مثبت. یعنی میگفتند این غول چراغ جادو تقریباً هر غلطی میتواند بکند).
این نوع نگاهها هم نشان میدهد که ما ظرفیتهای تکنولوژیهای مختلف و متعددی را که در سیستمهای Generative هوش مصنوعی به کار میروند، به درستی نمیشناسیم یا نقاط تشابه و تمایز آنها را نمیدانیم. مثلاً از تفاوت Inference Engine و Expert System و Language Model غافل میشویم و همین باعث میشود در برآورد فرصتها و تهدیدها و ضعفها و ظرفیتها خطا کنیم.
پیشنوشت سه – چهار: من خودم را یکی از علاقهمندان حوزهٔ محتوا میدانم (البته در کار تولید محتوا تقریباً هیچ سابقهای ندارم و در این فضا خودم را بیشتر به نویسندگی میشناسم). با توجه به این که یکی از کارکردهای اصلی سیستمهایی Pre-trained شبیه چت جی پی تی تولید محتواست، علاقهٔ چند ساله باعث میشود ترغیب شوم دربارهاش بنویسم.
پیشنوشت چهارم: قاعدتاً این مطلب به زودی جمع نمیشود و به پایان نمیرسد. من هم که خداوندگار نوشتن نیمهکاره هستم. اولویت فعلیام هم بحث فرهنگ است. با این حال امید دارم به اندازهای که دست و وقتم اجازه داد، این بحث را پیش ببرم و به جنبههای مختلفش بپردازم. این مطلب از جنس آموزش چت جی پی تی نخواهد بود. بلکه صرفاً در همین حد است که ببینیم چت جی پی تی چیست و استفاده از چت جی پی تی چه تأثیری بر آیندهٔ کسب و کارها و به طور خاص، صنعت محتوا دارد. اگر فرصت کافی دست دهد، بحثم را با خطرات چت جی پی تی به پایان میبرم و این که دسترسی به چت جی پی تی چه تأثیری بر زندگی روزمره ما و نیز فضای رقابتی میان کسب و کارها خواهد داشت.
جون کار چت جی پی تی از جنس حرف زدن است، طبیعی است که باید بحث را با «زبان» آغاز کنم. به این شکل، هم بهتر درک میکنیم که چی جی پی تی چگونه کار میکند و هم در ادامهٔ بحث متوجه میشویم که چه سوالاتی از چت جی پی تی بپرسیم تا پاسخهای بهتر و مفیدتری بگیریم.
زبان به عنوان زنجیرهای از کلمات
بیایید یک بازی بسیار ساده انجام دهیم. فرض کنید با قبیلهٔ جدیدی آشنا شدهاید و زبانشان را نمیشناسید. آنها از الفبای فارسی استفاده میکنند و نوشتن هم بلدند. آنچه در ادامه میبینید، بخشی از گفتگوهای آنهاست که در یک کتیبه ثبت شده.
لچفعغ مملا؟
فقی. مالابغ سیق بلیل.
لفعغ منل محح؟
فقی. قغیغ حخت منل.
قفب مالابغا قیصی قغیغ.
لفعغ غالع داغق عهب مملا؟
فقی. ضصسق عهچغ سیص عهب منل محح؟ صق.
قاعدتاً چیزی از این گفتگو متوجه نمیشوید. حالا به یک مسئله فکر کنید:
یک نفر از این قبیله چنین سوالی از شما میپرسد: «قغیغ حخت داغق مملا؟» به نظر شما پاسختان باید چه باشد؟ هیچوقت نمیشود با اطمینان کامل گفت. اما بر اساس دادههای موجود اگر جهان دانشتان به همین تکمکالمهٔ روی کتیبه محدود باشد، پاسخ خواهید داد: «فقی».
چرا؟ چون در دو نمونهای که سوالی با «مملا» به پایان رسیده، با «فقی» پاسخ داده شده است. حالا فرض کنید سوال دیگری از شما میپرسند: «مالابغا قیصی قغیغ غالق محح؟»
در اینجا بین دو گزینه گیر میکنید (باز هم بر اساس دادههای موجود). جواب احتمالاً باید یا «صق» باشد یا «فقی»
چون در متن دو سوال با محح به پایان رسیده و یک بار صق جواب گرفته و یک بار فقی.
البته ممکن است کمی پیچیدهتر هم فکر کنید که فعلاً به سراغش نمیرویم. ممکن است بگویید جواب «پرسش ۵ کلمهای که با «محح» تمام شده، صق بوده. بنابراین با توجه به این که پرسش جدید هم پنج کلمهای است، من بین «فقی» و «صق» ترجیح میدهم از صق استفاده کنم.
این بازی یک نکتهٔ مهم در خود دارد. شما در تلاش هستید بدون این که بفهمید دربارهٔ چه حرف میزنید، با طرف مقابل حرف بزنید. این روش عادی ما در گفتگو نیست. اما به هر حال، شکلی از تلاش برای گفتگو است.
شما با این سبک تلاش برای حرف زدن، یک نمونهٔ بسیار ابتدایی از هوش مصنوعی مکالمهمحور (Conversational AI) را شبیهسازی کردهاید.
این شکل از نگاه به زبان را میتوان «مدل کردن زبان به عنوان زنجیرهای از نمادها» یا «Modelling language as a sequence of symbols» نامید. به این معنا که شما میگویید از نظر من زبان یعنی کلماتی که پشت هم به زنجیر کشیده شدهاند و من معتقدم هر انتخاب حلقهٔ زنجیر به نوعی به این ربط دارد که حلقه یا حلقههای قبل چه بودهاند. هر چقدر بتوانم ویژگیهای این زنجیر را بهتر بفهمم و به شکلی تشخیص دهم که ارتباط کلمات متوالی چیست، راحتتر میتوانم به این زبان صحبت کنم.
از نظر ریاضی، مسئلهٔ بالا تفاوت جدی با این مسئله ندارد که به شما بگویند آخرین رقم از رشته اعداد زیر حذف شده و از شما خواسته شود بگویید در رشتهٔ زیر به جای X چه رقمی قرار میگیرد:
۳۴۳۵۴۳۴۵۳۲۴۳۲۵۳۴۵۳۴۲۵۳۴۲۳
۹۸۷۰۵۶۸۷۹۶۲۷۹۴۶۷۳۹۶۴۵۹۰۲۳۹
۶۹۷۲۴۶۲۳۰۴۶۷۹۲۳۷۶۴۹۲۶۳۴
۶۷۸۴۳۶۳۴۵۳X
و شما هم بخواهید جدول زیر را پر کنید:
احتمال این که ۰ باشد …٪ است
احتمال این که ۱ باشد …٪ است
احتمال این که ۲ باشد …٪ است
و …
مدلسازی زبان به عنوان زنجیره کلمات چه کاربردهایی دارد؟
فعلاً فرض کنید الگوریتمی طراحی کردهایم که فقط میتواند یک کلمهٔ بعد را در زنجیرهای از کلمات حدس بزند. خروجیاش هم شبیه همین چیزی است که کمی بالاتر دیدیم. یعنی چند کلمه پیشنهاد میدهد و میگوید که هر کلمه با چه احتمالی در ادامه خواهد آمد.
آیا چنین الگوریتمی به کار میآید؟
پاسخ مثبت است. با وجودی که این الگوریتم فعلاً در این مرحله بسیار ساده است، همچنان کاربردهای فراوانی دارد. به این چند نمونه توجه کنید:
پیشبینی کلمات هنگام تایپ
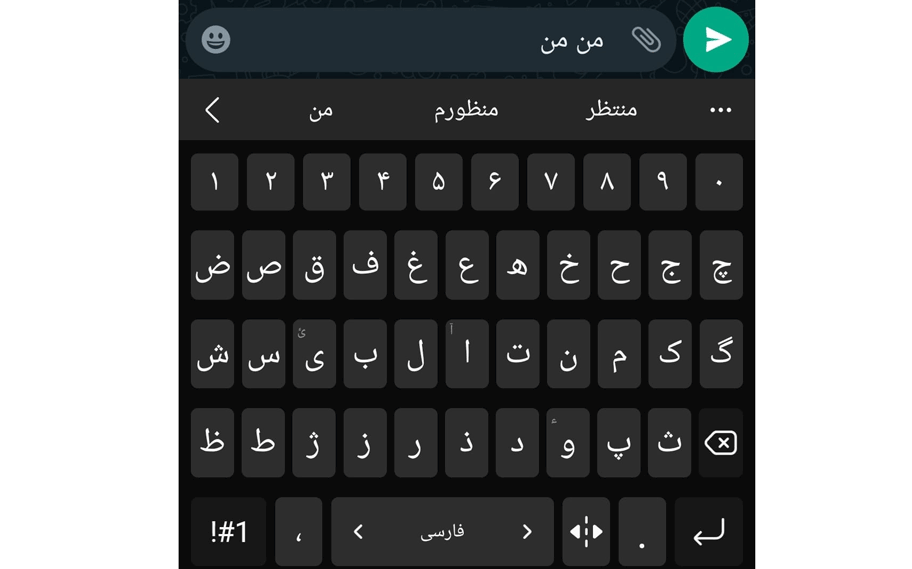
حتماً تا کنون کیبوردهای پیشبینیکننده یا Predictive Keyboards را دیدهاید. تقریباً تمام گوشیهای هوشمند موجود در بازار، میتوانند این قابلیت را در اختیار کاربران خود قرار دهند که با تایپ حروف اول یک کلمه (مثلاً هنگام تایپ مسیج) کلمهٔ بعدی را حدس بزنند.
تصویر زیر نمونهای از پیشبینی کیبورد سامسونگ است:
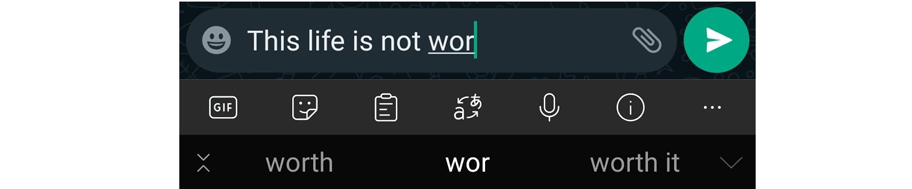
کیبورد مایکروسافت – نصب شده روی سیستم عامل اندروید – هم پیشبینیهای خودش را ارائه میدهد:

حدس زدن پرسش کاربران بر اساس نخستین کلمات آنها
اگر در گوگل، بینگ یا هر موتور جستجوی دیگری بخواهید سوال خود را در قالب یک عبارت یا جمله بپرسید، میبینید که آنها پرسشهای شما را حدس میزنند و بر اساس احتمال و میزان اطمینانی که به هر کدام دارند فهرست میکنند (Sorted by Confidence).
شبیه همین کار را در بخش FAQ و بخش ثبت تیکت برخی از سایتها هم میبینید. اگرچه این کارها بسیار شبیه همان Predictive Text Typing است، اما به خاطر برخی تفاوتهای ظریف – که خارج از بحث ماست – معمولاً آنها را زیر چتر Text Autocompletion قرار میدهند.
افزایش دقت OCR
تکنولوژی OCR یا Optical Character Recognition یکی از تکنولوژیهایی است که زندگی همهٔ ما را – حتی اگر ندانیم و متوجه نباشیم – تغییر داده است. هر وقت از یک متن عکس میگیرید و موبایلتان کلمات داخل متن را استخراج میکند، یا وقتی یک PDF قدیمی حجیم با صفحات اسکنشده دارید و میبینید که میتوانید کلمات مد نظرتان را داخل آن جستجو کنید، مشغول استفاده از دستاوردهای OCR هستید.
OCR تکنولوژی جدیدی نیست. دغدغهاش حدود یک قرن وجود داشته و نمونههای کاربردیاش نزدیک به نیم قرن است که وجود دارند. خود OCR در سادهترین شکل خود هم از هوش مصنوعی بهره میبرد و زیرمجموعهٔ الگوریتمهای تشخیص الگو (Pattern Recognition) محسوب میشود. همان الگوریتمهایی که اثر انگشت یا چهرهٔ ما را تشخیص میدهند. اما این تکنولوژی در ذات خود از جنس ترتیبی یا Sequential نیست. یعنی وقتی عکسی از یک متن را در اختیار OCR قرار میدهید، هر کلمه میتواند یک «مسئلهٔ جداگانه» باشد. به عنوان مثال در تصویر زیر، من با موبایلم از دستنوشتهام عکس گرفتهام و اپلیکیشن کلمات را تشخیص داده و جدا کرده است:
با این حال، مدلهای زنجیرهای از کلمات میتوانند به کیفیت کار OCR کمک کرده و خطای آن را کاهش دهند. مثلاً فرض کنید OCR توانسته عبارت feature of my Android را تشخیص دهد. حتی اگر کلمهٔ phone را بدخط و ناخوانا نوشته باشم، حدس زدن این کلمه دشوار نیست.
برای این که بهتر بتوانید کاربرد تحلیل زنجیرهای در OCR را درک کنید، در کیبورد پیشبینیکنندهٔ سامسونگ چند کلمه تایپ کردم:
همانطور که میبینید، یک تحلیل سادهٔ زنجیره نشان میدهد که کلمهٔ بعدی من به احتمال زیاد یکی از سه کلمهٔ phone و app و device است. پس همین که OCR بتواند تشخیص دهد که دستخط من به کدامیک از سه کلمه نزدیک است، برای تشخیص کلمه کافی است. یا اگر بخواهم دقیقتر بگویم: بعد از این که OCR حدس زد کلمهٔ من phone است، میتواند با تحلیل مدل زنجیرهای، اطمینان خود را از نتیجهی محاسباتش افزایش دهد.
این کار را میتوان Sequence Modeling Assisted OCR نامید. این نوع استفاده از الگوریتمها به عنوان دستیار یکدیگر در دنیای هوش مصنوعی بسیار رایج است.
کمک به نرمافزارهای تبدیل صدا به متن
نرمافزارهای تشخیص صدا (Speech Recognition) و تبدیل صدا به متن هم از جمله نرمافزارهای پرکاربرد در سالهای اخیر هستند. بسیاری از ما از سرویسهایی مثل Google Voice Typing استفاده کردهایم. قدیمیترها هم بیش از دو دهه است که با نرمافزارهایی مانند Dragon Naturally Speaking که هماکنون شرکت نوانس آن را عرضه میکند کار کردهاند (Nuance اکنون در مالکیت مایکروسافت است). Dragon آنقدر تخصصی شده که اگر وکیل یا مذاکرهکننده و تنظیمکنندهٔ قراردادهای بینالمللی باشید، به جای نسخهٔ معمولی نرمافزار تشخیص صدای خود، نرمافزار Dragon Legal Anywhere را به شما عرضه میکند تا در تشخیص صدای شما و تبدیل آن به کلمات و متن قرارداد، کمترین خطا به وجود بیاید.
همهٔ نرمافزارهای تشخیص صدا از مدلسازی زنجیرهٔ کلمات استفاده نمیکنند. بسیاری از آنها صرفاً یک شبکهٔ عصبی متعارف هستند که با صدا و متن آموزش دیدهاند. مثلاً فرض کنید شما هزاران کتاب صوتی دارید که خوانندگان حرفهای آنها را خواندهاند. از سوی دیگر متن همان کتابها را هم در اختیار دارید. اگر شبکهٔ عصبی با این دادهها آموزش ببیند (Train شود) میتواند با دقت قابلقبولی صدا را تشخیص دهد. منظورم از Train شدن، به سادهترین زبان، این است که کلمه به کلمه و جمله به جمله، صدا را به شبکهٔ عصبی بدهند و به شبکه بگویند که هر صدا با چه کلمهای متناظر است. بعد از مدتی که شبکه تلفظهای متعددی از یک کلمه را دریافت کرد و آموزش دید، میتواند تلفظهایی را هم که اندکی تفاوت دارند تشخیص دهد.
اما همین نرمافزارهای نشخیص صدا، اگر به مدلسازی زنجیرهٔ کلمات مجهز شوند، خطای آنها بسیار کمتر خواهد شد. مثلاً اگر عبارت The Universal Laws of Life and Death را برای یک برنامهٔ تشخیص صدا بخوانید و Death را نامفهوم تلفظ کنید، یک برنامهٔ شبکهٔ عصبی که تحلیل زنجیرهای انجام نمیدهد، ممکن است آن را there تشخیص دهد. اما مدلسازی زنجیرهٔ کلمات هم به کمکش بیاید، میداند که بعد از of Life and بعید است کلمهٔ there وجود داشته باشد و احتمالاً کلمهٔ death تلفظ شده است.
در واقع اگر در سالهای اخیر میبینیم اغلب ما میتوانیم به سادگی با نرمافزارهای Voice Typing حرف بزنیم و جملاتمان هم با دقت خوبی تشخیص داده میشود، بیشتر از این که نشاندهندهٔ بهبود تلفظ ما باشد، ناشی از تقویت موتورهای تشخیص صدا با پشتیبانی مدلهای زنجیرهٔ کلمات است.
دو رویکرد متفاوت به مدلسازی زبان
هر چه تا اینجا گفتیم، فقط دربارهٔ یک فرض بود: «فرض زبان به عنوان یک زنجیره از نمادها.» حالا سوال این است که این زنجیره از نمادها را با چه رویکردهایی میتوان تحلیل کرد.
برای مدلسازی هر زنجیرهای از نمادها دو رویکرد وجود دارند که بسیار شناختهشده هستند و به کار ما میآیند. برای کسی که قرار است صرفاً کاربر چت جی پی تی باشد، همین که کلیت این دو رویکرد را بشناسد کافی است. حتی با یک شناخت اندک هم میتوان نقاط قوت و ضعف چت جی پی تی (و سایر مدلهای هوش مصنوعی پردازش زبان طبیعی) را تا حد خوبی درک کرد.
یک رویکرد مدلسازی زبان، مدلسازی بر مبنای احتمال است. چنین مدلهایی را Probabilistic Language Models مینامند. مثالی که من اوایل همین مطلب آوردم، با رویکرد احتمالی بود. چون تقریباً همهٔ حرفهایم از این جنس بود که «معمولاً وقتی کلمهٔ … در جمله میآید، احتمال این که کلمهٔ … بعد از آن بیاید زیاد است.»
رویکرد دومی که در مدلسازی به کار میرود، استفاده از شبکه های عصبی و یادگیری عمیق است. در ادامه هر یک از این دو رویکرد را در چند جمله توضیح میدهم (با قربانی کردن کامل دقت علمی، البته بدون این که به هدف بحث خدشهای وارد شود).
مدلسازی مبتنی بر احتمال
در این روش، شما هر چقدر میتوانید متن جمع میکنید. متن اخبار، روزنامهها، کتابها، گفتگوها و …
سپس تصمیم میگیرید که زنجیرهٔ چند کلمهای برای شما مهم است. مثلاً ممکن است بگویید من فقط میخواهم دو کلمه را معیار قرار دهم. یعنی اگر دیدم «سیب قرمز» و «سیب سرخ» و «سیب رسیده» و «سیب کال» و «سیب درشت» در متنها زیاد به کار رفته، دیگر هر جا سیب دیدم، فرض میکنم بعد از سیب باید یکی از کلمهها باشد. خودم هم جایی سیب را به کار بردم، اگر خواستم کلمهای به آن اضافه کنم، از همینها استفاده میکنم.
حالا یک نفر میپرسد: کلمهٔ قبل از سیب برایت مهم نیست: «مثل سیب …» و «این سیب …» و «برایم سیب …» را یکجور فرض میکنی؟
شما میبینید بهتر است سه کلمه را در نظر بگیرید. چون «مثل سیب …» با کلماتی مثل سرخ و رسیده کامل میشود. اما «برایم سیب …» علاوه بر سرخ و درشت و … میتواند با «بیاور» و «پوست» و … هم کامل شود (برایم سیب بیاور. برایم سیب پوست بکن و …).
به این نوع مدلسازی احتمالی n-gram میگویند. n تعداد کلماتی است که در آمارگیری و محاسبهٔ احتمال لحاظ میکنید. روش دو کلمهای را Bi-gram میگویند. روش سه کلمه را Tri-gram میگویند و …
اگر گفتند n-gram منظور این است که همهٔ ترکیبهای n کلمهای را استخراج کردهاند و هر وقت n-1 کلمه را به آنها بدهید، از روی گزارشهای آماری خود حدس میزنند که برای آخرین حلقهٔ این زنجیر (کلمهٔ n ام) چه گزینههایی و با چه احتمالی وجود دارد.
این روش ظاهراً جذاب به نظر میرسد. اما ضعف بزرگی دارد و آن این است که این نوع تحلیل زنجیره، بیحافظه است (Memorylessness).
بگذارید این مفهوم را با یک مثال ساده نشان دهم. فرض کنید تحلیل five-gram انجام میدهیم (پنج کلمه را با هم در نظر میگیریم). من چهار کلمهٔ اول یک ترکیب پنجکلمهای را به شما میدهم و از شما میخواهم با توجه به دادههای آماری خود بگویید کلمهٔ پنجم چیست:
«نظام جمهوری اسلامی در …»
چه ایدههایی در مورد کلمهٔ پنجم دارید؟ چهل، این، عالم، جهان، ناتوانی، ناکارآمدی، جریانسازی، قلب، ایران، همهپرسی، روزهای، همهٔ، عرصهٔ، طول، بخش، مواجهه، مقابل، شکل، مدار، مسیر، برابر، مراحل، اندیشه، صدر و …
طبیعتاً بر اساس دادههای خود میتوانید برای هر یک از این کلمات (و دهها کلمهٔ دیگر که میتوانند به عنوان کلمهٔ پنجم بیایند) یک احتمال حدس بزنید. اما همه میدانیم که این کلمات از زمین تا آسمان با هم فرق دارند. این جمله در زبان یکی از مسئولان نظام، یک روزنامهنگار، تریبون نماز جمعه، یکی از براندازها، یک اصلاحطلب، یک کاندیدای نمایندگی مجلس و … میتواند به شکلهای متفاوتی تکمیل شود. اگر تحلیل خود را از five-gram به six-gram ارتقاء دهیم، کمی وضع بهتر میشود. همینطور اگر سیستم هوشمند خود را به seven-gram و eight-gram و … برسانیم،نتایج رضایتبخشتری خواهیم داشت.
وقتی میگوییم Memorylessness یا بیحافظگی، منظورمان این است که در n-gram برای سیستم ما اصلاً فرق نمیکند که قبل از این n کلمه چه چیزی گفته شده است. و همین بیتوجهی به گذشته، باعث میشود خطای الگوریتم افزایش پیدا کند.
متخصصان ریاضی معمولاً این نوع نگاه به متن را رویکرد مارکوفی مینامند. چون مدل مارکوف در احتمال به سراغ مدلسازی پدیدههایی میرود که «فرض میکند» گذشتهٔ آنها برای دانستن آیندهشان مورد نیاز نیست.
سادهترین مثال زنجیره مارکوف، پرتاب سکه یا همان شیر یا خط کردن است. به شما میگویند که سکهٔ سالمی روی زمین افتاده است. سکه را برمیداریم و پرت میکنیم تا دوباره روی زمین بیفتد، چقدر احتمال دارد که وضعیت سکه تغییر کند؟ (اگر شیر بوده روی خط بیفتد و اگر خط بوده روی شیر بیفتد). شما به سادگی میگویید ۵۰٪. آیا برایتان مهم است که قبلاً که با این سکه بازی کردهاند شیر آمده یا خط یا با چه ترتیبی شیر و خط آمده؟ قطعاً نه.
حتی اگر سکهٔ شما سالم نباشد و اصطلاحاً Unfair باشد، یعنی مثلاً احتمال شیر آمدن ۴۰٪ و خط آمدنش ۶۰٪ باشد، باز هم پرتاب سکه را میتوان با زنجیره مارکوف مدل کرد. چون همین که احتمال ۴۰٪ و ۶۰٪ را میدانید (که یک ویژگی ثابت سکه است) و وضعیت الان سکه را میدانید، میتوانید احتمال تغییر وضعیت را حساب کنید. اتفاقهای گذشته و این که قبلاً به چه ترتیبی شیر یا خط آمده، هیچ تأثیری رو پیشبینی شما ندارد. سکهٔ ۴۰ / ۶۰ را در نظر بگیرید:
شیر – خط – شیر – شیر – خط – شیر – خط – بعدی ؟
شیر – شیر – شیر – خط – خط – خط – خط – بعدی؟
در هر دو حالت، شما باید با احتمال ۴۰ – ۶۰ دربارهٔ وضعیت بعدی حرف بزنید. این که چند بار آخر چه اتفاقی افتاده، مهم نیست.
زنجیره مارکوف Memoryless یا بیحافظه است (دقیقتر بگویم: برای مدلسازی رویدادهای بیحافظه و ناوابسته به گذشته به کار میآید). زنجیره مارکوف در پیچیدهترین حالت خود میگوید: «آینده فقط تابع حال است و نه گذشته.» در n-gram هم دقیقاً همین کار را میکنیم. مثلاً در five-gram میگوییم: من برای تشخیص کلمهٔ پنجم، فقط به چهار کلمهٔ قبل نگاه میکنم. اصلاً مهم نیست که کلمات قبل از آن چه بودهاند.
با این حال، نباید قدرت زنجیره مارکوف را دستکم بگیریم. همین شیوهٔ n-gram بسیاری از کارهای تحلیل زبان طبیعی را به خوبی انجام میدهد. تقریباً تمام مثالهایی که در بالا گفتم، یعنی تشخیص صوت و تشخیص دستنوشته و مانند اینها میتواند با دقت قابلقبولی با همین الگوریتم های آماری انجام شود.
توضیحی که خیلی مهم نیست | آیا اگر ما ظرفیت محاسباتی نامحدود داشتیم و مثلاً میتوانستیم به جای five-gram سراغ five-hunred-gram برویم و همهٔ الگوهای قبلی را هم با هم ترکیب کنیم، این سیستم بینقص میشد؟ یعنی مثلاً شما دادههای دو-گرام و سه-گرام و چهار-گرام و پنجگرام تا پانصد-گرام را گردآوری کنید و با ترکیب آنها (به شکلی که فعلاً برایمان مهم نیست) یک الگوریتم پردازش زبان طبیعیِ احتمالمحور بسازید.
پاسخ این است که: نه! مشکل دیگر این روش، Overfitting است. دادههای بیشتر میتوانند کار را خراب کنند. اگر Overfitting را نمیشناسید، این چند خط را نادیده بگیرید | پایان توضیحی که خیلی مهم نبود.
مدل زبانی با تکیه بر شبکه های عصبی
دومین روشی که برای مدلسازی زبان (یا هر زنجیرهای از نمادها) به کار میرود، استفاده از شبکه های عصبی (Neural Networks) است. ایدهٔ شبکه های عصبی ایدهای نسبتاً قدیمی است. البته معمولاً هر چندسالیکبار با یک نامگذاری جدید دوباره شنیده و شناخته میشود. مثلاً شاید برایتان جالب باشد که کسانی که امروز از یادگیری عمیق و Deep Learning حرف میزنند، تقریباً مبتنی بر روشی کار میکنند که حوالی ۱۹۵۰ ابداع شد و و البته حدود ۱۹۸۰ تحولی بنیادین را تجربه کرد. بعد از آن، اگر چه پیشرفتهای مهمی در یادگیری با شبکه های عصبی انجام شده، اما آنقدر که بعضی تازهمتخصصان هوش مصنوعی دربارهاش به ما میگویند، بنیادین نبوده است (این توضیح از آن جهت مهم است که از اسمها و اصطلاحات عجیبی که این روزها میشنوید نترسید).
بگذارید با یک مقایسهٔ استعاری توضیح دهم.
اگر کارهای دههٔ پنجاه دونالد هِب (Donald Hebb) را – در مدلسازی عملکرد نورون و یادگیری در آن – شبیه کارهای کوپرنیک و کپلر در نظر بگیریم، نسل جدیدی از شبکه های عصبی را که در دههٔ هشتاد شکل گرفت، میتوان گامی بزرگ به اندازهٔ کار نیوتن تلقی کرد. حالا به یک طراح سیستمهای دینامیکی خودرو فکر کنید که سه قرن بعد از نیوتن، خودروهای امروز ما را طراحی میکند. به یک معنا، میتوان گفت او خیلی جلوتر از تفکر نیوتنی است. به معنایی دیگر، او هنوز هم شکل توسعهیافتهٔ همان مدل را بهکار میگیرد.
ماجرای شبکه های عصبی هم همین است. گام بزرگ اول را دونالد هب برداشت. دوران هب دوران جدیدی بود که ما نورون را یک المان نسبتاً ساده دیدیم که سینگالهای الکتریکی را پردازش میکند (قبل از آن از جن و موجودات غیرارگانیک تا روح، بسته به باورهای شما، در سوراخهای بین همین نورونها لانه کرده بودند). در دههٔ هشتاد، این ایده مطرح شد که اگر ما تعدادی نورون را شبیهسازی میکنیم، چرا از خروجی خود نورونها به عنوان ورودیشان استفاده نکنیم؟ (فرض کنید یک نفر امروز بگوید: چرا چت جی پی تی فقط باید متنهای انسانی را بخواند؟ میتوانیم خروجیهای خود چت جی پی تی را هم به خودش بدهیم تا آنها را هم بررسی کند و الگوی یادگیری خودش قرار دهد). ایدهٔ ورودی گرفتن از خروجی، ظاهراً ساده است، اما ویژگیهای دینامیکی سیستم را بهکلی عوض میکند و ظرفیتهای جدیدی برای آن میسازد. این شبکهها که آنها را با نام RNN (مخفف Recurrent Neural Networks)سالها وجود داشتند و از آنها استفاده میشد، تا ایدههای جدیدی برای بهبود ظرفیت پردازش آنها شکل گرفت (هم برای عمق پردازش و هم برای پردازش موازی). اصطلاحاتی مثل Attention Mechanisms (مکانیزمهای توجه) و Self-attention (توجه به خود) که بعداً با نام شیکتر و جذابتر Transformerها همراه شدند، به این نوع تغییرات اشاره دارند.
اما با همهٔ این تغییرات و تحولاتی که طی نزدیک به نیم قرن اخیر در شبکه های عصبی به وجود آمده، دو ویژگی که نقطهٔ قوت و ماهیت شبکه عصبی را تشکیل میداده تغییر نکرده است: ذخیره سازی توزیع شده، خاطره داشتن از گذشته (ویژگیها بیشتر است. دو مورد به کار ما میآید).
این دو ویژگی بسیار مهم هستند و هر چقدر آنها را بهتر درک کنیم، ظرفیتها و محدودیتهای شبکه های عصبی و مدل های زبانی مبتنی بر شبکه های عصبی (مانند Chat GPT) را بهتر درک خواهیم کرد.
یک مثال بسیار سادهشده از یادگیری توزیعی (شبیه شبکه عصبی)
دوستانی که با شبکه های عصبی و یادگیری ماشینی آشنایی دارند، اگر مثال زیر را با الگوهایی که از شبکه های عصبی در ذهن دارند مقایسه کنند، احتمالاً از سادهسازی بیشازحد من خوشحال نمیشوند. اما اگر بپذیرند که صرفاً میخواهیم با مفهوم توزیعشدگی (مستقل از پیچیدگیهای شبکه های عصبی و سیستمهای یادگیری عمیق) آشنا شویم، به گمانم این مثال را خواهند پسندید. این مثال صرفاً از این جهت به ذهنم رسید که الان یک فروشگاه عطر روبهرویم قرار دارد و فروشنده مدتی است که با جدیت من را نگاه میکند. اگر جای دیگری نشسته بودم و چیز دیگری جلوی من بود، مثال دیگری میزدم.
فرض کنیم به یک کارگاه سادهٔ تولید عطر رفتهایم. این کارگاه، پنج مادهٔ مختلف دارد که آنها را به نسبتهای متفاوت با هم ترکیب میکند و انواع عطرها را میسازد.
چهار نفر هم داریم که سلیقهٔ عطر نسبتاً متفاوتی دارند. هر عطری که از این کارگاه بیرون میآید، به هر چهار نفر عرضه میشود و هر کدام صرفاً با یک کلمه پاسخ میدهند: پسندیدم. نپسندیدم.
فرض کنید من یک دستگاه به شکل زیر درست کردهام:
روی این دستگاه ۳۵ ولوم (شبیه ولوم رادیو – پتانسیومترهایی که برای تنظیم صدا و … استفاده میکنیم) قرار دارد و بالای آن چهار عدد لامپ نصب شده است. این پتانسیومترها با مدار پیچیدهای که ما اطلاعی از آن نداریم به هم وصل هستند. و احتمالاً خروجی بعضی از آنها ورودی چند پتانسیومتر دیگر را تأمین میکند. به هر حال، هیچ نوع دسترسی به داخل جعبه نداریم و برایمان مهم هم نیست.
اما میدانیم که وقتی پتانسیومترها را میچرخانیم، در بعضی محدودهها که قرار میگیرند، بعضی از این لامپها خاموش یا روشن میشوند.
حالا میتوانیم یک بازی جالب انجام دهیم:
من به شما ترکیب مواد یک عطر را میگویم: ۲۳٪ از مادهٔ یک و ۲۷٪ از مادهٔ دو و ۳۰٪ از مادهٔ سه و ۲۰٪ از مادهٔ چهار و ۰٪ از مادهٔ پنج.
همچنین به شما میگویم که این عطر را نفر اول و دوم و چهارم پسندیدند و نفر سوم آن را نپسندید.
شما باید پنج پتانسیومتر سمت چپ را بر اساس ترکیب مواد عطر تنظیم کنید. سپس با سی پتانسیومتر دیگر آنقدر بازی کنید تا چراغهای بالا دقیقاً مشابه نظر آن چهار آدم روشن شوند. یعنی چراغ اول و دوم و چهارم روشن شوند و سومی خاموش بماند.
تا اینجای کار بازی سخت نیست. اما حالا میتوانیم یک گام جلوتر برویم.
مشخصات عطر بعدی را به شما میدهم: ۵٪ – ۱۰٪ – ۱۰٪- ۲۰٪ – ۵۵٪ و باز هم نظر آن چهار نفر: اولی و چهارمی پسندیدند.
حالا شما باید باز با پتانسیومترها بازی کنید. و دنبال تنظیمی بگردید که چراغ اول و چهارم را روشن کند. اما باید سعی کنید این تنظیم را طوری انجام دهید که اگر دوباره پتانسیومترهای چپ را روی همان تنظیم قدیمی (۲۳-۲۷-۳۰-۲۰-۰) بردیم، چراغها مشابه حالت اول روشن شوند (اول. دوم و چهارم).
این بازی را میتوانیم دهها بار با عطرهای مختلف انجام دهیم. کمکم دستگاه شما به نقطهای میرسد که اگر ترکیب عطری را به شما بگویم که قبلاً نگفته بودم، دستگاه میتواند حدس بزند که کدامیک از این چهار نفر آن را میپسندند و کدام نمیپسندند.
خوشبختانه اوضاع در دنیای هوش مصنوعی بسیار بهتر است. چون رابطهٔ بین این پتانسیومترها را میدانیم. همچنین محققان هوش مصنوعی سالها جستجو کردهاند و توانستهاند پتانسیومترهایی با ویژگیهای مناسب بسازند که ورودیها را به شکل کارآمدی ترکیب کند و خروجی بدهد. ضمناً الگوریتمها و روشهای متنوعی هم ایجاد شده که کمک میکند شما پتانسیومترها را به شکل بهینهای تنظیم کنید. یعنی به شکلی که تا حد امکان، نتایج قبلی از بین نرود و ظرفیت تحلیل نمونههای جدید هم به سیستم اضافه شود.
اما فعلاً بحث ما این نیست. ما با همان جعبهٔ خودمان کار داریم. چون فقط میخواهیم مفهوم Distributedness یا توزیعشدگی را بفهمیم.
بعد از این که چند روز با دستگاه بازی کردید و پتانسیومترها را تنظیم کردید، نهایتاً تمام تلاش شما در یک ماتریس ۵ در ۶ خلاصه میشود. مثلاً چیزی شبیه این:
هر عددی که در این جدول میبینید، متناظر با یکی از پتانسیومترها در اسباببازی بالاست. عملاً تمام تلاش شما و یادگیری شما و آنچه از سلیقهٔ آن چهار نفر میدانید، در این جدول خلاصه شده است.
چند اتفاق جالب که در این جدول افتاده را با هم مرور کنیم:
یکی اینکه دادههای این ماتریس، کاملاً توزیعشده هستند. شما نمیدانید و نمیتوانید بگویید کدام عدد به سلیقهٔ چه کسی مربوط است. فقط میتوانید بگویید تمام چیزی که از سلیقهٔ این آدمها دارم در این جدول ذخیره شده است.
دیگر اینکه این ماتریس، حافظه دارد. یعنی تمام نمونههایی که به آن نشان دادهاید و تجربیاتی که داشته، به نوعی جایی در آن ذخیره شده است. شما طبیعتاً هر بار سعی میکنید با کمترین تغییر در تنظیمات پتانسیومترها، کاری کنید که اسباببازیتان با نمونهٔ حدید هم جور در بیاید و بتواند آن را هم تحلیل کند.
سوم این که در n-gram سیستم شما عملاً میتواند در مورد زنجیرههایی که قبلاً دیده و در پیکره یا دیتابیس آن وجود داشته اظهارنظر (قابلاتکا) کند. اما در اینجا سیستم این ظرفیت را دارد که در مورد ترکیب عطری که پیش از این هرگز ندیده هم (طبیعتاً با یک محدودهٔ خطا) نظر بدهد. یعنی یک ترکیب عطر را که اصلاً تا حالا وجود نداشته به آن بدهید و حدس بزند که چه کسانی آن را میپسندند.
سلام محمدرضای عزیز
ممنونم که در این مورد هم نوشتی.
یک سوال داشتم
استفادهی این ابزارها برای کار تولیدمحتوا (که امروزه هم خیلی داره فراگیر میشه) کار مناسبی هست؟ اینکار احتمال تکراری شدن مفاهیم رو بالا نمیبره و یا از تولید محتوای جدید جلوگیری نمیکنه؟
مثل خیلی از تکنولوژی های دیگه که انسان در طول تاریخ دیده، با این هم کم و بیش مثل قبلیا برخورد میشه.
یه عده ازش میترسن، یه عده عاشقش میشن، یه عده بیش از حد بزرگش میکنن و یه عده بیش از حد دست کم میگیرنش
ولی بعد از فرونشست هیجانات اجتماعی و گذر از دینامیکی که ایجاد کرده، به نظرم تا حد زیادی یک انقلاب محسوب میشه. منظورم از انقلاب، انقلاب علمی هستش. حداقل ش اینه که عموم مردم رو با هوش مصنوعی و آینده تکنولوژی آشنا میکنه.
و من امیدوار و منتظرم که ما انسان ها ازش استفاده کنیم و برای مشکلات پیچیده بشر و جوامع ازش بهره و کمک بگیریم. مشکلاتی مثل آلودگی هوا، گرم شدن زمین، بیماری های لاعلاج یا صعب العلاج، و … و دنیا رو بجای قشنگی برای زندگی همه نوع موجودات در کنار هم تبدیل کنیم.
و
و امیدوارم تکنولوژی بجای اینکه انسان ها رو از هم دور و دور تر بکنه، به هم نزدیک بکنه.
یا ما ازش درست استفاده بکنیم و بجای دور شدن از هم، بهم نزدیک و همدل بشیم
سلام محمدرضا،
امیدوارم که این روزها سرِ حال باشی.
توی چند ماهی که گذشت، دستم به نوشتن نمیرفت. حتی به خوندن هم نمیرفت. درگیر یک شوک شده بودم. اگر بخواهم اون رو توصیف کنم، شاید بشه این طور گفت:
یک مجسمهای داری و تا امروز فکر میکردی از طلای خالص هست و میلیلاردها تومان ارزش دارد و تو همهی منابع زندگیات را پای آن گذاشتی یعنی فکرت را، انرژیات را، مهمتر از همه وقتت را… و بعد یک دفعه متوجه میشوی که مجسمهای که آنقدر ازش مراقبت میکردی و برایش اهمیت قائل بودی، یک مجسمهی پلاستیکیِ زرد رنگ بوده که آن را ۵ هزار تومان هم از تو خریداری نمیکنند.
چند روزی هست که کم کم از اون شوک خارج شدم، حالا احساس میکنم دیگر هیچ وقت نمیتوانم مثل گذشته فکر کنم یا رفتار کنم. الان که فکرش را میکنم کاملاً از تغییرات اخیری که برایم اتفاق افتاده، خوشحالم.
راستش اخیراً دو تا از کتابهای اشعار افشین یداللهی بهم هدیه رسیده و واقعا دیوانهکننده است. احساس میکنم تا حالا کسی این قدر ساده و عاشقانه شعر نگفته، باید اعتراف کنم گاهی به مخاطبِ اشعارش حسودی میکنم!
دو قطعه شعر را از کتاب «مشتری میکدهای بسته» / انتشارات نگاه برایت مینویسم:
شماره ۱۳ – صفحه ۳۶ و ۳۷:
روزی که
برای اولین بار
تو را خواهم بوسید
یادت باشد
کارِ ناتمامی نداشته باشی
یادت باشد
حرفهای آخرت را
به خودت
و همه
گفته باشی
فکر برگشتن
به روزهای قبل از بوسیدنم را
از سَرَت بیرون کن
تو
در جادهای بیبازگشت قدم میگذاری
که شباهتی به خیابانهای شهر ندارد
با تردید
بیتردید
کم میآوری
شعر شماره ۲ – صفحه ۱۴
ما
به پای هم پیر نمیشویم
به دست هم پیر میشویم
———————————————————————————-
ارادت و اخلاص تام و تمام
امیرعلی
سلام و عرض ادب
روز معلم رو با تاخیر تبریک میگم.
یکی خوش شانسی های زندگی من، آشنا شدن با شما بوده و از این اتفاق خیلی خیلی خوشحالم.
امیدوارم که برقرار باشید و سرحال.
ارادتمند
خسرو جان سلام.
من هم – با عذرخواهی زیاد – با تأخیر تشکر میکنم و ممنونم از محبتت.
یکی دو ماه پیش، توی جمع همکارهای متمم داشتیم در مورد بعضی از دوستامون که قدیمیتر هستن و همیشه هم هستن، اما خیلی بیسروصدا هستن حرف میزدیم. چند تا اسم به ذهنمون رسید. یکیش تو بودی.
اما این بیسروصدا بودن باعث نمیشه که ما لطفها و محبتها رو هم یادمون بره.
محمدرضا جان سلام. روز معلم مبارک.
بجز چیزایی که مستقیم از خودت یاد گرفتیم، بابت کامیونیتیای که ساختی هم ممنونم. هیوا یکی از کسانیه که من ازش خیلی یاد میگیرم و یه جورایی برام توی یه حوزههایی معلم بوده و این به واسطهی فضایی بوده که تو فراهم کردی.
البته معلمی تو یه چالشی هم داره :)، اونم اینه که معیار معلمی برای من، تو یا افرادی هستند که تو بهشون اشاره میکنی و اینجوری دیگه سخت میشه همه رو معلم دونست. البته بیتشر منظورم جنبهی شخصیتی معلمیه و نه محتوایی که آموزش داده میشه.
روزت مبارک.
اگر نوروز، سالگرد تولد و یا حتی سالگرد متمم رو تبریک نگیم، روز معلم که روز شما است رو باید تبریک گفت.
آقامعلم روزتون مبارک. ممنون برای همه درسهای زندگی و مدیریتی که در این سالها به ما دادی
مجید جان. فاصلهٔ بین پیام تو و پاسخ من خیلی زیاد شده. توضیح خاصی هم ندارم براش بدم. هر بهانهای بوده قبلاً آوردهام و تکرار توضیح این که تراکم کارها چهجوریه و چرا در پاسخ دادن به حرف دوستانم کُند و تنبل شدهام، کمک چندانی نمیکنه.
ولی خواستم بگم که حتی وقتهایی که بسیار خسته یا خوابآلوده یا بیحوصلهام و دستم به نوشتن نمیره یا حتی لپتاپ رو نمیتونم باز کنم و چند خط بنویسم، دیدن همین پیامهای کوتاه چندخطی توی روزنوشته، حالم رو خیلی خوب میکنه.
خصوصاً از طرف دوستان قدیمی مثل تو که آدم وقتی اسمشون رو میبینه، حتی پیش از باز کردن پیام و اطلاع از محتواش، احساس خوشحالی و امنیت داره و میدونه چیزی که قراره بخونه بهش انرژی میده.
مواظب خودت باش.
سلام
خیلی خیلی روز معلم رو تبریک میگم
من از شما و بستری که شما فراهم کردین خیلی چیزا یاد گرفتم
همیشه قدردانم
مخلصم حمید جان.
ممنونم از لطفت. خوشحال شدم اسمتو دیدم.
امیدوارم علاوه بر حال خودت، حال خدمت از ما هم خوب باشه. این چند وقت چند بار به بهانههای مختلف یادت افتادهام و دو جا هم حرفت شده (به قول معروف: ذکر خیر). هی امید داشتهام که کمی ذهنم بازتر و سبکتر بشه بعد احوالپرسی کنم. اما ظاهراً امید عبثی بوده؛ لااقل تا الان.
لطف شما همیشه شامل حال من بوده و بابتش ممنونم
بیشتر برای این موضوع کامنت دوباره گذاشتم:
قبلا که روی کامنت، پاسخ می دادید ایمیل ارسال می شد. گفتم اطلاع داده باشم که این دفعه ایمیل ارسال نشده
چنانچه خودتون از این موضوع اطلاع داشتید، لطفا این کامنت من رو نادیده بگیرید
سلام و درود و عرض تبریک بر معلم گرامی
شادی و سلامت و آرامش دل، آرزوی ما برای معلم دوست داشتنی مون هست.
با درود ادب
ارادت
مخلصیم محمدرضا خان
روزتون مبارک
انشالله سایه تون مستدام باشه
سلام مسیح جان.
امیدوارم حالت خوب باشه.
از لطفت ممنونم. خیلی خوشحال شدم اسمت و پیامت رو اینجا دیدم.
بعضی از اسمها خیلی خوب یاد آدم میمونه. اسم تو هم برای من همینطوره. جدا از کامنتهای خوبت توی متمم که اکثراً تحلیل و تجربهٔ شخصی خودته و باعث شده که حس کنم سالهاست پای حرفت نشستهام و چیزهای زیادی ازت شنیدهام، یه کامنت خاص هم داری که تا حالا بارها اینور اونور نقل کردهام. خیلی ساده است و شاید به نظر خودت چیز خاصی نیاد. اما خب. خیلی به کار من اومده (ممکنه جزئیات رو اشتباه بگم).
یه جا تعریف کرده بودی که چند تا خربزه یا هندونهفروش یا گوجهفرنگیفروش کنار هم توی جاده بودن. یکیشون عکس بزرگ محمدرضا گلزار رو بالای سرش زده بوده با یک تابلو دستش که قیمت میوه رو اعلام کرده بوده. و اتفاقاً فروشش هم بیشتر بوده.
این ماجرای کوتاه و ساده که نقل کردی، بارها در فضاهای مختلف به کار من اومده (در توضیح این که بخشی از association و image و value creation برندها کاملاً خارج از اختیارشون شکل میگیره. و علاوه بر این، به عنوان سندی در تأیید این که در شرایط نسبتاً برابر، هر شکلی از جلب توجه میتونه مصداق تمایز باشه).
خلاصه گفتم فرصت خوبیه که تشکر کنم.
سلام و عرض تبريك خدمت معلم بي ادعاي عاشق محمدرضاي گرامي، روزتون مبارك. ?
قربانت سکینه جان. امیدوارم خوب و خوش باشی.
یه مدت نسبتاً زیادی ازت خبر نداشتم. خیلی خوشحال شدم اسمت رو اینجا دیدم.
يك دنيا سپاس از مهر سرشارتون محمد رضاي عزيز
اصل خبر شمائيد!
از بلند اقبالي ماست كه شما رو داريم. اينكه هنوز مي نويسيد، مي آموزيد، آگاهي مي بخشيد و خدمت ميكنيد خودش نعمت بزرگي براي ما.
كم سعادتي از من بوده كه ناخواسته كمي دور افتادم از اينجا. با اين حال هنوز هم مشتاقانه مطالب و محتواهاي ارزشمندتون رو ميخونم و ياد ميگيرم.
من هم بسيار خوشحال شدم از جواب شما. گمان نمي كردم با مشغله زيادي كه داريد پاسخ كامنت هارو بديد و الا زودتر به اينجا سر ميزدم.
در پناه خدا شاد و سلامت باشيد
سلام استاد.
اخیرا خیلی پرحرفی کردم ولی حیفم اومد روز معلم رو به شما تبریک نگم. تو یکسال گذشته من از شما، وبلاگتون و حرفهاتون بیشتر از هر دانشگاهی یاد گرفتم. روزتون مبارک.
سلام محمدرضای عزیز
روزت مبارک معلم،
هر آنچه خواهان آنی برایت آرزو میکنم ?
با سلام
معلم عزیز خواهشمند است سریعتر این مطلب را تکمیل کنید سرعت و حجم انتشار اخبار در حوزه هوش مصنوعی آنچنان زیاد است که واقع تحلیل شما زیر این بمباران خبری می تواندهرچند کوچک یک پناهگاهی ذهنی باشد
روز معلم رو بهتون تبریک میگم امیدوارم شاگرد خوبی باشم.
امیرمحمد جان.
ممنونم ازت.
و ببخش که دیر جواب دادم. داشتم فکر میکردم که کمی بده که اینقدر با تأخیر دارم جواب میدم. اما بعد دیدم، دیر جواب دادن بهتر از هرگز جواب ندادنه. خصوصاً این که اولین کامنتت اینجاست (تا حدی که من یادمه و وردپرس هم اینطور نشون میده).
امیدوارم بازم وقت کنی و اینور حرف بزنی. در متمم اونقدر مواظب هستیم که اصول و قواعد رعایت بشه، عملاً یک بخشی از «فضای امکان» برای گفتگو و تعامل و موضوعات قابلبحث، از دست میره و گفتگوهامون محدودتر میشه.
محمدرضای عزیز خیلی ممنونم ازت که جواب دادی. دیر و زودش مهم نیست. خیلی خوشحال شدم.
بله اولین کامنتم هست بیشتر همین گوشه کنار میشینم و سعی میکنم از شما و دوستای خوبم یاد بگیرم.
ممنون که مینویسی و حرف میزنی.
بهترین و شریف ترین و دلسوزترین معلم دنیا روزتان مبارک?
سلام محمدرضا. خوشحال شدم که دیدم مطلبی با این عنوان نوشتی.
حرفهایی که اینجا میگم بیشتر از نوع بلند فکر کردن هست. این نوع مکالمات رو با دوستانم هم داشتهام ولی اینجا خیلی برام متفاوته. خیلی دوست دارم اگر فرصتی داشتی نظرت رو در این موارد بهم بگی. البته میتونم با رویکردی که در متن پیش گرفتی حدس بزنم که نظراتمون تا حدی نزدیکه.
دوران ارشدم داره کمکم تموم میشه و دارم مصاحبه کاری میرم.
برام جالبه که توسعه Chatbotها خیلی تو مصاحبهها عنوان میشه. هر شرکتی میخواد یه چتبات توسعه بده که جایگزین بسیاری از نیروهای پشتیبانی بشه. فکر میکنم در بسیاری از موارد (مخصوصا مواردی که داکیومنت شدهاند) یه چتبات بسیار سریعتر، کمهزینهتر و دقیقتر از یک انسان خواهد بود و جایگزینی مفید است.
البته اینها توی شرکتهای چابکتر مطرح میشه. جاهایی مثل بانکها (یا همین سیستم آموزشی خودمون) خیلیوقتها به آدم به عنوان یک سیستمی که «حفظ میکنه» میبینند و همین رو معیار ارزیابی قرار میدن. همین میشه که الان به سادگی میشه تو بسیاری از این جنس آزمونها نمره بسیار خوبی رو با ابزارهایی مثل Bard و Bing AI کسب کرد بدون این که حتی لای کتاب رو باز کرده باشیم.
چیزی که مدتی هست بهش فکر میکنم اینه که مدلهای زبانی در حال حاضر نمیفهمند و حفظ میکنند. البته حفظ کردن رو بسیار خوب انجام میدن و تو فهمیدن هم تا حدی ترجمه و تفسیر رو انجام میدن ولی برونیابی نه.
به سختی هم میتونم تصور کنم که مدلهای الان چیزی از جنس «تفکر» (مثلا سیستمی یا استراتژیک) یا خلاقیت داشته باشند یا این که خطاهای شناختی که انسان داره رو نداشته باشند.
اینها به نحوه مدلسازی ما از مسئله برمیگرده که در سادهترین همیشه حالت میخوایم Likelihood رو بیشینه کنیم. بعد با همین منطق میایم تسکهایی مثل Masked LM یا Next Sentence Prediction رو تعریف میکنیم و مدل رو روی اون آموزش میدیم (+).
پس میایم دو تا تسک تعریف میکنیم که یکی سعی میکنه یک سری لغت رو از متن جا بندازه و مدل سعی میکنه پیشبینیاش کنه. تسک دوم هم سعی میکنه به مدل آموزش بده که آیا دو جمله دقیقا در یک متن پشتسرهم بودهاند یا نه.
این روش باعث شکلگیری چیزی مثل تفکر سیستمی نخواهد شد. این روش «در بهترین حالت»، مدلی رو بهمون میده که در بسیاری از جاها فقط بلده کلیگویی کنه. کلیگوییهایی که به درد هیچچیز نخواهند خورد. برای تست این مسئله کافیه در مورد مباحث قدری چالشیتر مثل دین یا سیاست یا موضوعات تابو از این جنس ازشون سوال بپرسید (البته باید بتونید که جوری پیام بدید که مکانیزمهایی که برای کنترل مدلها در نظر گرفتند، نتونه تشخیص بده).
علتی که این رو میگم دقیقا تسکهایی هست که مدلها روی اونها آموزش داده شدند. این تسکها نهایتا یک «ماشین آماری زبانی» یا همچین چیزی بوجود میاره.
به همین خاطر حرف بسیاری از آدمهایی که راجع به پتانسیلهای این مدلها اغراق میکنند رو نمیفهمم. وقتی ما میایم زبان – که بزرگترین دستاورد بشریت بوده – رو با تسک Masked LM بهش یاد میدیم و خلاقیت رو یک نویز گوسی تعریف میکنیم، حرف زدن از جایگزینی کامل انسان با این مدلها دور از ذهنه. مدلهای زبانی الان نهایتا میتونند جای انسان در کارهایی که به حفظکردن (و تا حدی فهمیدن) مربوط هستند رو بگیرند.
نهایتا حرفم این که ما نمیتونیم چیزهایی که هنوز دقیقا نمیفهمیم (مثل خلاقیت و تفکر) رو با روشهای فعلی مدلسازی کنیم و اگر بخوایم به سطوح بالاتر دست پیدا کنیم باید چیزی از جنس پارادیم شیفت داشته باشیم (نه حتی نزدیک به کارهایی که الان انجام میشه).
پینوشت: اینطور که من مقالات فیلد NLP (و کلا هوشمصنوعی) رو میبینم کمتر به این موضوعات توجه میشه. بسیاری از مقالات، «نگاه پازلی» به هوشمصنوعی دارند و یک قطعهاش رو برمیدارند و یک سری قطعات دیگه رو با آزمون و خطا به جاش جایگذاری میکنند و خوشحال میشن که با این کار – در رقم سوم بعد از اعشار – تونستند دقت یا صحت مدل رو افزایش بدن. ژورنالها به سرعت مقالات رو چاپ میکنند و اساتید هم خوشحال هستند که مقالاتشون cite میخوره و دانشجو هم خوشحاله که استادش راضیه. دانشگاه هم با معیارهای خودش فکر میکنه کار مهمی داره انجام میده ولی ته تهش فیلد جلو نمیره و همونجایی هستیم که چند سال پیش بودیم (البته قبول دارم چند سال یک بار، یکی با طرز فکر «چشمها را باید شست» میاد و واقعا فیلد متحول میشه. مقالاتی مثل AlexNet و Attention از این نوع هستند ولی چند تا از این مقالات داریم؟).
امیر جان. سلام.
چون بحث تو کمی جلوتر از چیزیه که من الان نوشتهام و من باید توی این نوشته چند گام دیگه بنویسم تا به این حرف تو برسم، و از طرفی حیفم میاد الان همینطوری این حرف تو رو رها کنم، فقط چند جملهٔ کوتاه مینویسم تا متن اصلی جلوتر بره.
اول این که به نظر من هم تعبیر «ماشین آماری زبان» که تو به کار بردی، برای ابزارهایی که الان دارن با Deep Learning زبان یاد میگیرن تعبیر درست و دقیقی هست.
دوم این که الگوهای تفکر مثال تفکر استراتژیک و تفکر سیستمی، الگوهایی هستند که بر اساس مدلسازیهای علّی و استتناجی و روی ساختارهای Hierarchical Representation کار میکنن (حداقل بر اساس ابزارهای فعلی که ما در دسترس داریم). بنابراین طبیعیه که حداقل الگوهای فعلی تولید زبان طبیعی، نتونن از عهدهٔ این کار بربیان. چون اینها برای درک Vocaublary World ساخته شدهان و نه Event World یا Physical World یا … اینها جهانی رو دارن که مولکولهاش کلمه است. اتمهاش حروف و کاراکتره. اشیاءش جمله هستند. سازمانهاش متن هستند و …
و البته برای درک این جهان، واقعاً قدرتمندند.
سوم این که از یه منظر دیگه، بعضی از رفتارهای الگوهای فکری-زبانی رو میشه از جنس Emerged Behavior دونست. به عنوان نمونه: خلاقیت. یعنی به سادگی نمیشه در مورد این که آیا خلاقیت چیزی خارج از قلمرو این الگوهاست، نظر داد. همین باعث میشه عدهای به ظرفیتهای آتی این سیستمها امیدوار باشند.
چهارم این که اساساً جهان ما همینقدر کور جلو رفته. البته تلفات و هزینه هم کم نداشته (اساساً مکانیزم Evolution یکی از کندترین و پراتلافترین مکانیزمهاییه که بشر تونسته تا کنون کشف کنه). به عنوان یه مثال ساده، یکی از هزینههای تکامل از موجود تکسلولی به انسان دقیقاً همون چیزیه که ما امروز در قالب برخی عزیزانی میبینیم که اختلالهای ژنتیکی دارند. در واقع، از لحاظ تئوریک، نمیشه جهانی رو در نظر گرفت که از موجود تکسلولی به انسان برسه، اما یه سری انسانها در اون با اختلال ژنتیکی به دنیا نیان.
وقتی تکامل کور میتونه در طول زمان (البته خیلی طولانی و با اشتباهات زیاد)، رفتارها و ویژگیهای بسیار پیچیدهای رو بروز بده، ما باید به این هم فکر کنیم که پتانسیل مدلهای آماری میتونه فراتر از چیزی باشه که ما الان برآورد میکنیم.
مثلاً فرض کن سیستمهای GPT چند سال انرژی بذارن و صدها میلیارد کلمه متن تولید کنن. بعد همون متنها به خودشون Feed بشه و با خروجی خودشون Train بشن. یه نگاه سطحی میگه خب اینطوری که اتفاق عجیبی نمیفته. اما میدونیم که این شکل از فید کردن دادهها، چیزی میسازه که میتونه بسیار بسیار بسیار متفاوت از مدل اولیه باشه (اساساً RNN ها با همین ایدهٔ ساده، تحول بزرگی در محاسبهٔ ماشینی ایجاد کردن). کل جهان هم چنین چیزیه. طبیعت یه سری موجود Generate میکنه. و اون موجودات خودشون دوباره طبیعت رو در طول زندگیشون با رفتارهاشون Feed میکنن. بعد هم طبیعت اونها رو دوباره میکُشه و بعد از مرگ، Decompose میکنه و دوباره Feed میشه به خودش. حاصل هم به قول دنیل دنت این بوده: From Bacteria to Bach. از باکتری تا باخ.
میخوام بگم این موضوع که GPTها میتونن با متن خودشون Train بشه، اصلاً توانمندی کوچیکی نیست و نباید ازش غافل باشیم و میتونه چیزی با ماهیت و ظرفیتی فراتر از ماهیت و ظرفیت اولیهشون ایجاد کنه.
پنجم اینکه میدونیم هوش مصنوعی عملاً داخل دانشگاهها Develop نمیشه. داخل دانشگاهها، «مقاله» و «استاد دانشگاه» تولید میشه. بنابراین به نظرم این که دانشگاه و دانشگاهیها اساساً راجع به هوش مصنوعی چی فکر میکنن یا چه مقالاتی مینویسن، اصلاً مهم نیست. البته گاهی خروجیهاشون میتونه الهامبخش باشه و قطعا گاهوبیگاه استفاده میشه. اما اصل ماجرای هوش مصنوعی در لابراتورهای شرکتهای بزرگی توسعه پیدا میکنه که منابع و دانش این حوزه رو دارن و قطعاً هم نه تمایلی به انتشار عمومیش دارند و نه انگیزهای (و مهمترین ریسورسهاش رو هم دارن: برق و دیتاست).
ششم این که مدلهایی مثل Attention قطعاً جذاب هستن و نقش بزرگی در توسعه سیستمهای Generative و Sequence Analysis داشتن. اما از یه منظر دیگه هم میشه بهشون نگاه کرد. منطقی بود Attention به این شکل، از لایههای پایینتر در شبکه عصبی Emerge بشه. نه این که ما بیایم به زور با الگوریتم، Attention و تحلیل Short Context و Long Context رو «بچپونیم» داخل سیستم. به نظر میاد اگر در آینده ساختار پایهٔ شبکههای عصبی به شکل بهتری طراحی بشن، نیازی به این جور تحمیلهای بیرونی نباشه.
شبیه این اتفاق در مورد پردازش زبان طبیعی هم افتاده. بیست سال پیش، همهٔ دنیا مدام دنبال جا دادن ساختارهای تکمیلی و فرایندهای مکمل در الگوریتمهای تولید زبان طبیعی بود. و خیلی هم هیجانزده میشدن با این کار.
بعد از مدتی، الان که Language Modelهای جدید اومدهان، متوجه میشیم که اون زمان انسان درگیر Fine Tune کردن سیستمی بوده که ظرفیتهاش به شکل بنیادی محدودیت داشته.
از پاسختون خوشحال شدم. از دیروز دارم به حرفهاتون فکر میکنم. در لابهلای حرفها به نکتهای اشاره کردید که میخوام بیشتر بازش کنم.
وقتی داشتم کتاب سیستمهای پیچیده شما رو میخوندم، به فکرم رسید اگر بتونیم یک مدل هوشمصنوعی الهام گرفته از اون سیستمها داشته باشیم، احتمالا پیشرفت مهمی خواهیم داشت.
تو مدلسازیهای فعلی یک Global Loss رو به زور (از خارج) به مدل تزریق میکنیم و مجبورش میکنیم تو یک تسک خاص (نه عمومی) چیزی که ما میخوایم رو یاد بگیره و اتفاقا خوب هم یاد میگیره.
ولی مکانیزم Evolution، هرگز Global Loss نداشته. هر نود بصورت مستقل یک Local Loss (به نام بقا) داشته که در یک تعامل پیچیده با بقیه اعضا مشخص میشده و سیستم بهینه میشده.
اینطوری در طول زمان، یک سری سیستم به نام انسان بوجود اومده که با این که تابع Loss خودش بقا هست ولی در تعامل با هم چیزی به اسم سازمان رو تشکیل میده یا در مورد مفهومی به نام آزادی حرف میزنه.
با این رویکرد چیزی مثل Object Detection هدف سیستم نخواهد بود (که با یک Global Loss آموزشش بدیم). بلکه نتیجه جانبی تعریف یک Local Loss بسیار بسیار متفاوته. البته نمیدونم اون Local Loss چی باید باشه.
شبکههای گرافی نزدیکترین چیز به ایدهای هست که دارم ولی احساس میکنم هنوز خیلی با اون چیزی که من از سیستمهای پیچیده میفهمم متفاوته.
البته یه راه دیگه اینه که بصورت کور همون مکانیزم Evolution رو با چیزی مثل الگوریتم ژنتیک شبیهسازی کنیم و امیدوار باشیم که با صرف هزینه بسیار زیاد شاید به سیستمی (حتی پیچیدهتر از انسان) برسیم ولی احتمالا این چیزی نیست که الان قابل انجام باشه.
به هر حال اینها ایدههایی بود که داشتم (و البته چند بار جاهای مختلف گفتم ولی کسی نفهمیده که دقیقا چی میگم شاید به این دلیل که خودمم دقیقا نمیدونم چی میگم و اگر میدونستم تا حالا پیادهسازیاش کرده بودم) ولی گفتم شاید شما بتونید تکمیلترش کنید یا سرنخهایی برای مطالعه بیشتر بهم بدید.
با مهر
امیر
سلام آقای شعبانعلی عزیز
خیلی خوشحال شدم در اینباره مطلب گذاشتید. این روزهایی که تمام وقت دارم میخونم و امتحان میکنم تا حس عقب افتادن از دنیای جذاب هوش مصنوعی رونداشته باشم٬ هر محتوایی در اینباره که شما بنویسید برام نوید بخش آگاهیه. نمیدونم چرا از جمله اینکه هوش مصنوعی ترسناکه و جای خیلی مشاغل رو داره میگیره خوشم نمیاد٬ حس میکنم معادل همون مقاومت های بشر در مواجهه با دنیای صنعتی یا دیجیتاله. فقط سرعت تغییری که هوش مصنوعی ایجاد کرد برای من غافلگیر کننده بوده. نسل من از ویندوز ۹۸ تا سیستم عاملای گوشی همراه رو قدم قدم جلو اومد ولی الان ناگهان با کلی تغییر مواجه شدم که در چند مورد گیج کننده بوده. اولیش یافتن جایگاه خودمون به عنوان یک ایرانیِ به دور از امکانات و جدا افتاده است. که نمیدونم تا کی و چقدر محدودیت ها باعث خواهد شد که ما نتونیم قدم به قدم با مردم دنیا جلو بریم و به این دنیای جدید و بزرگ متصل باشیم. دومین چالش که فکر میکنم هنوز نیاز به گذر زمان داره مساله چگونگی برخورد با هوش مصنوعی و قوانین و محدودیت هاییست که شاید لازم باشه در نظر گرفته بشه و هنوز شفاف نیست. مثلا یاد مبحث [نتیکت] افتادم که بارها خود شما هم مطرح کردید. اینکه هنوز بعد از گذشت چندین سال فرهنگ جا افتاده ای در شبکه های اجتماعی وجود نداره.درباره هوش مصنوعی هم ذهنم درگیره همین مساله شده. که هم به شکل جهانی چارچوب هایی ممکنه براش قرار بدند و هم به خصوص در ایران که کلا منکر وجود تغییر و همگام سازی با دنیا هستیم چه اتفاقاتی رخ میده. مثلا در رشته من (فشن) مقاله ای اخیرا میخوندم با این موضوع که حق مالکیت طرح هایی که با هوش مصنوعی ایجاد میشه و اجرا میشه با کیه و به چه صورته. میتونم بگم مقاله هم پایان بازی داشت و خیلی قانعم نکرد. برای همین فکر میکنم با همین سرعتی که هوش مصنوعی داره همه چیز رو تغییر میده با همین سرعت لازمه درباره تاثیراتش تحقیق کنیم و خودمون رو برای چگونگی برخورد و استفاده ازش آماده کنیم. بیصبرانه منتظر ادامه مطلبتون هستم.